
Understanding RAFT: Adapting Language Models to Domain-Specific Retrieval Augmented Generation
Introduction
In the landscape of language models, pretraining on extensive corpora has become the standard. However, the need to adapt these models to specific domains, incorporating new and relevant knowledge, remains a significant challenge. This paper introduces Retrieval Augmented Fine Tuning (RAFT), a novel training strategy aimed at enhancing a model’s ability to perform well in domain-specific, “open-book” settings by improving how it handles and integrates external documents during question-answering tasks.
Background and Motivation
Large Language Models (LLMs) like GPT-3 have demonstrated impressive capabilities in general knowledge tasks. However, in specialized domains such as legal, medical, or specific enterprise environments, general knowledge isn’t enough. These models must accurately utilize specific documents to answer questions, akin to preparing for an “open-book” exam where the correct use of external sources is crucial.
RAFT: The Core Concept
RAFT stands for Retrieval Augmented Fine Tuning. The methodology focuses on training the language model to:
- Organizing the training dataset: so that a portion lacks the golden documents in their context which contains answer. This step is essential for the training step.
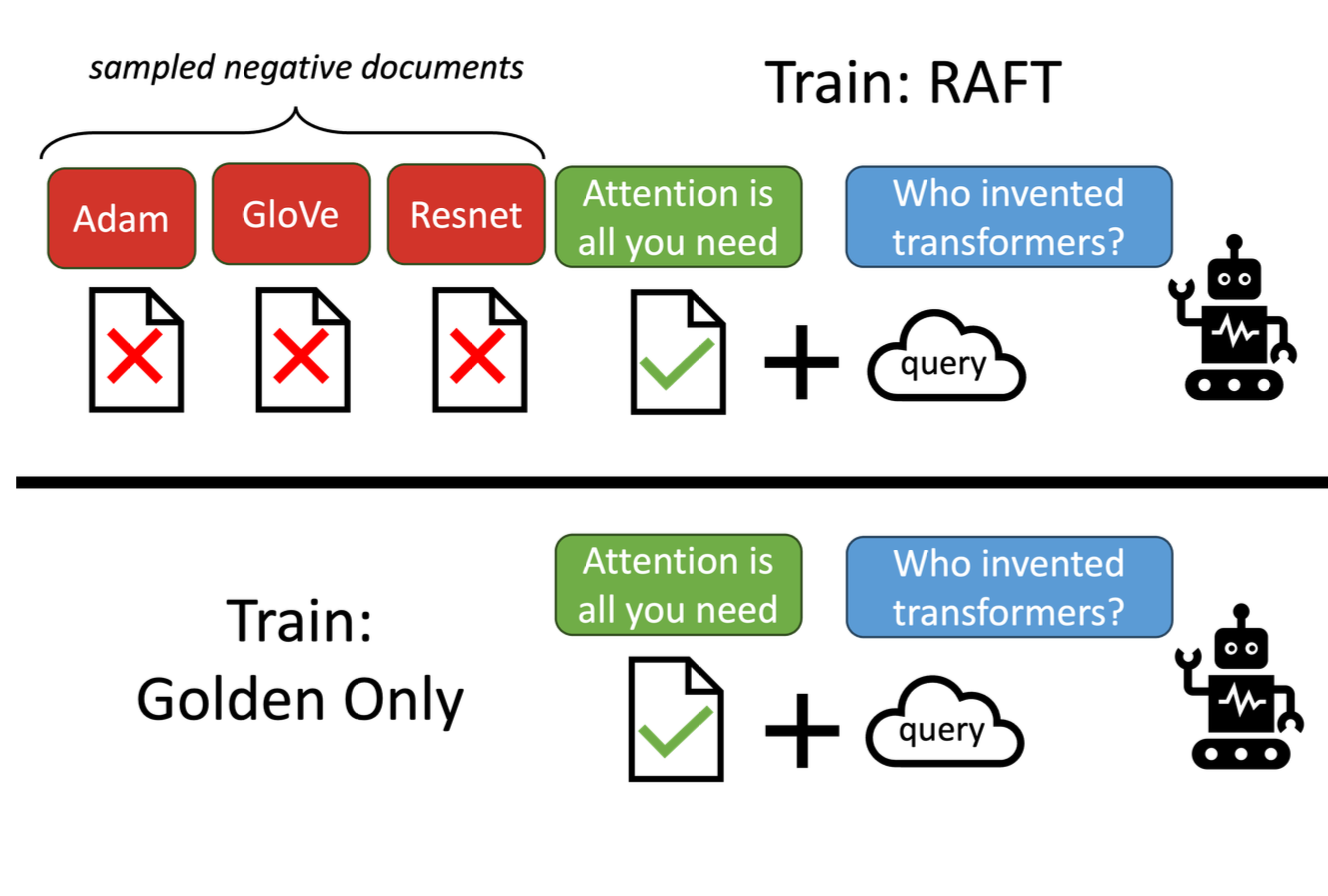
Training the model alongside Distractor Documents: LLMs are vulnerable to irrelevant text in the documents. Therefore, training the model alongside distractor documents improves the model’s ability to discern and disregard irrelevant content, focusing solely on pertinent information. This in turn improves the LLM’s capability to answer questions based on the context rather than memorizing.
Utilize Chain-of-Thought Reasoning: Encourage detailed, step-by-step reasoning based on the relevant documents to formulate answers with direct quotations.

Methodology
Supervised Fine-Tuning: Traditional fine-tuning involves training on question-answer pairs without leveraging external documents at test time. This method fails to prepare models for scenarios requiring document integration.
RAFT Training:
- Training Data Setup: Each training instance includes a question (Q), relevant documents (D), distractor documents (Dk), and a chain-of-thought style answer (A).
- Handling Distractors: Some training examples include only distractor documents to force the model to learn when not to rely on external texts.
- Answer Generation: The model is trained to generate answers by referencing the most relevant parts of the provided documents, forming a reasoning chain.
Experimental Setup
Datasets: The paper evaluates RAFT using various datasets, including:
- PubMed QA: Biomedical research questions.
- HotpotQA: Multi-hop question answering based on Wikipedia.
- Gorilla APIBench: Generating correct, functional API calls based on documentation.
Baselines:
- Zero-shot Prompting: Using pre-trained LLMs without any document reference.
- RAG: Combining LLMs with a retriever to reference documents at test time.
- Domain-Specific Fine-Tuning (DSF): Fine-tuning models on domain-specific data without retrieval.
- Domain specific Finetuning with RAG (DSF + RAG): Equip a domain specific finetuned model with external knowledge using RAG. So, for the “knowledge” the model does not know, it can still refer to the context.
Results
RAFT significantly outperforms traditional fine-tuning and retrieval-augmented methods across various domains. Key findings include:
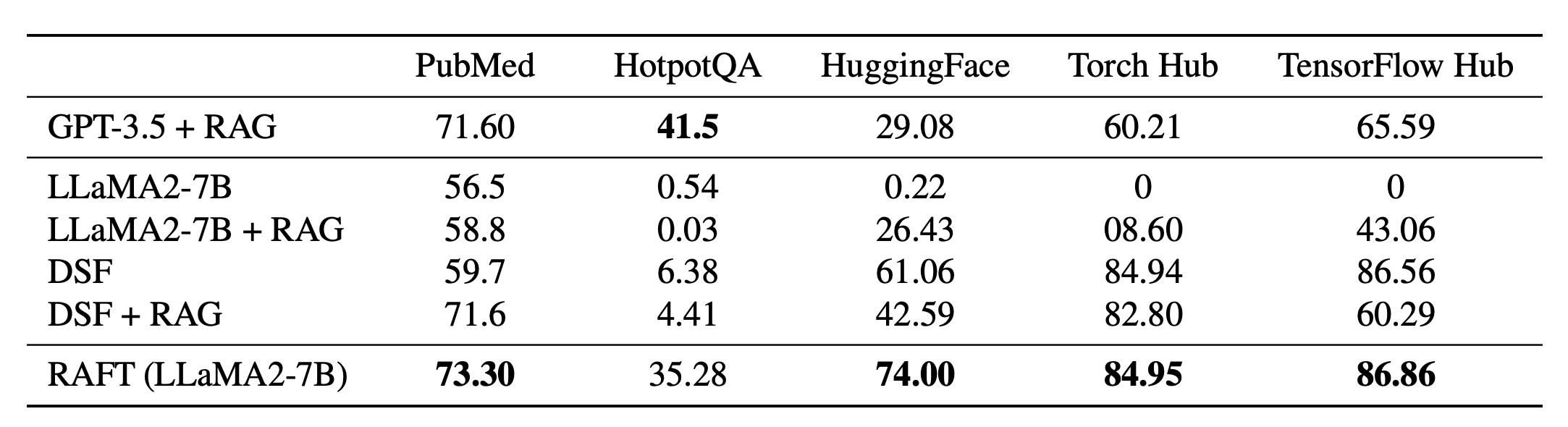
- Enhanced Robustness: RAFT-trained models effectively handle distractor documents, improving accuracy in retrieval-augmented tasks.
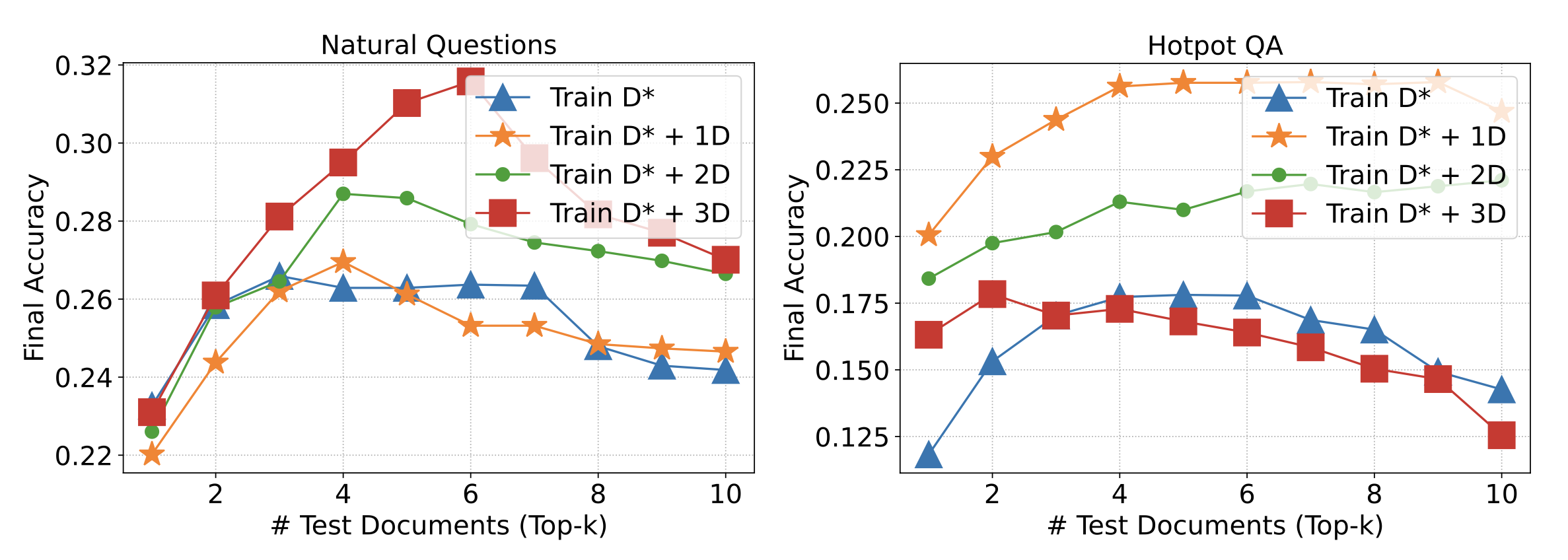
- Chain-of-Thought Benefits: Integrating detailed reasoning chains boosts the model’s ability to derive correct answers from the provided context.

- Optimal Training Setup: Incorporating a mix of relevant and irrelevant documents during training enhances the model’s performance in real-world scenarios.
Practical Implications
RAFT presents a practical approach to preparing LLMs for specialized tasks, making them robust and accurate in handling domain-specific information. This methodology is particularly beneficial in fields like medicine, law, and enterprise solutions, where precise and contextually accurate responses are crucial.
Conclusion
RAFT offers a significant advancement in adapting large language models to domain-specific tasks by integrating retrieval-augmented generation with fine-tuning. The approach not only improves the model’s accuracy but also its ability to handle and prioritize relevant information, making it a valuable tool for specialized applications.
For further details, code, and demonstrations, the RAFT implementation is open-sourced at GitHub.