
Introduction to LoRA and Full Fine-Tuning
Fine-tuning LLMs like Llama-2, with billions of parameters, requires significant computational resources. Traditional full fine-tuning adjusts all the parameters of a pre-trained model, demanding extensive memory and processing power. LoRA offers an alternative by adapting only low-rank perturbations to specific weight matrices, significantly reducing the memory footprint.
In this blog, we will explore the paper LoRA Learns Less and Forgets Less
The Core Findings of the Paper
The research compared LoRA and full fine-tuning across two main domains: programming and mathematics. The comparison involved two types of training regimes: instruction fine-tuning (IFT) using structured prompt-response pairs and continued pretraining (CPT) with unstructured tokens.
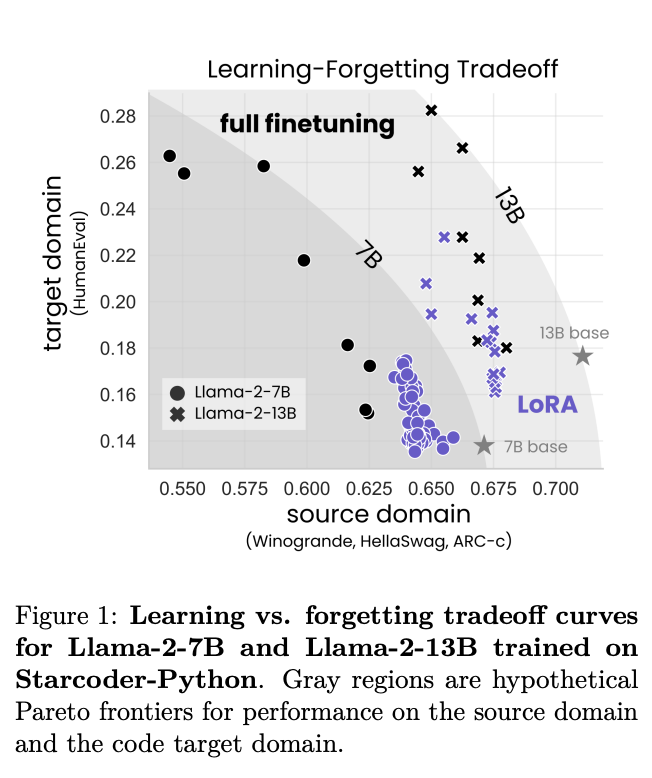
Key Outcomes:
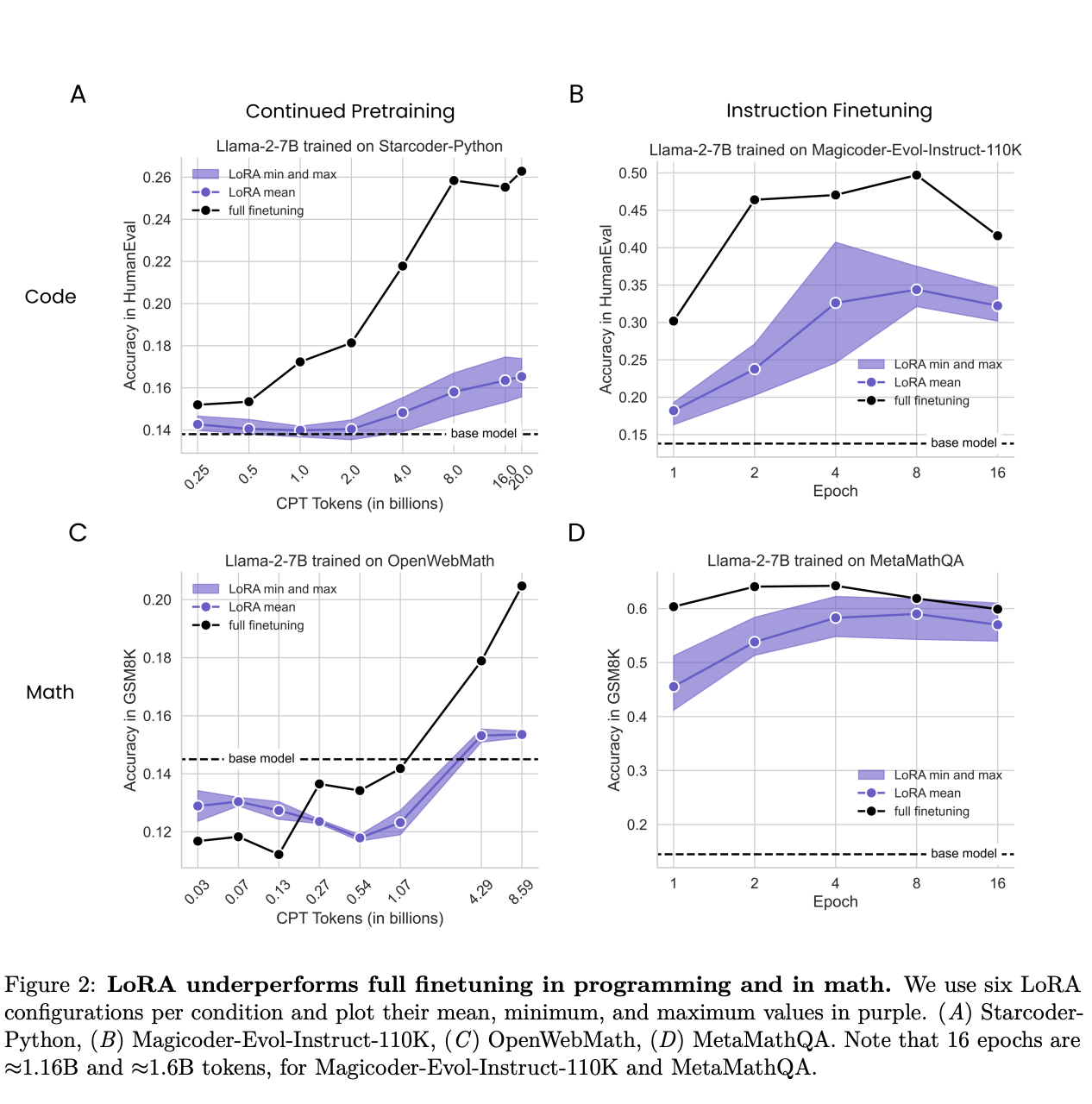
- Performance: LoRA generally underperforms compared to full fine-tuning in target domain tasks, particularly in programming. However, in mathematics, LoRA narrows the performance gap, suggesting domain-specific effectiveness.
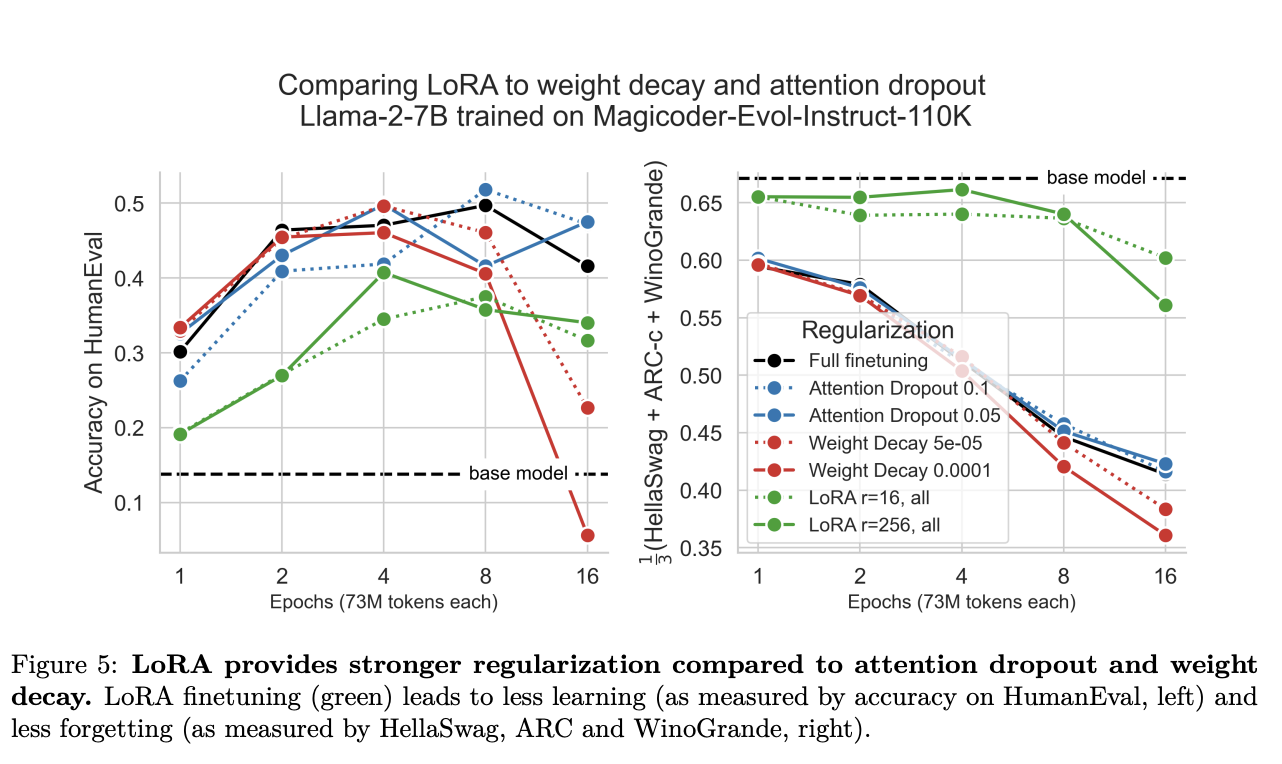
- Regularization and Forgetting: LoRA acts as a stronger regularizer, effectively mitigating the forgetting of source domain knowledge. This is particularly valuable in scenarios where maintaining performance on previously learned tasks is crucial.
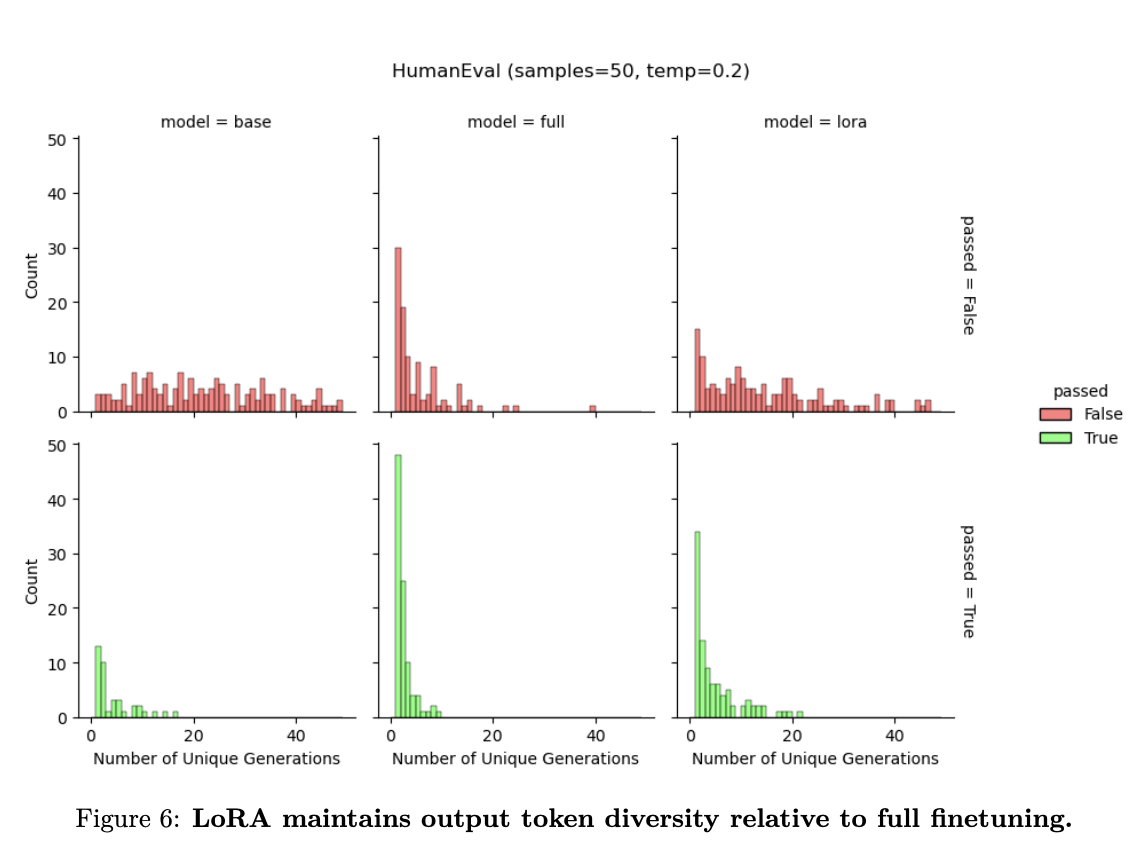
- Diversity of Generations: Unlike full fine-tuning, which tends to limit diversity in generated solutions (a phenomenon known as “collapse”), LoRA maintains a broader array of potential outputs, preserving the model’s versatility.
Why Does LoRA Underperform?
The paper hypothesizes that the relatively simpler tasks used in prior studies might not have fully revealed the limitations of LoRA. Through rigorous testing, it was found that full fine-tuning often leads to high-rank perturbations—complex changes to the model’s weight matrices—which are crucial for solving more complex problems like those in coding and math domains.
Practical Implications and Recommendations
For practitioners, the study offers valuable insights:
- Parameter Sensitivity: LoRA’s effectiveness is highly dependent on the choice of learning rates and the specific model weights it targets.
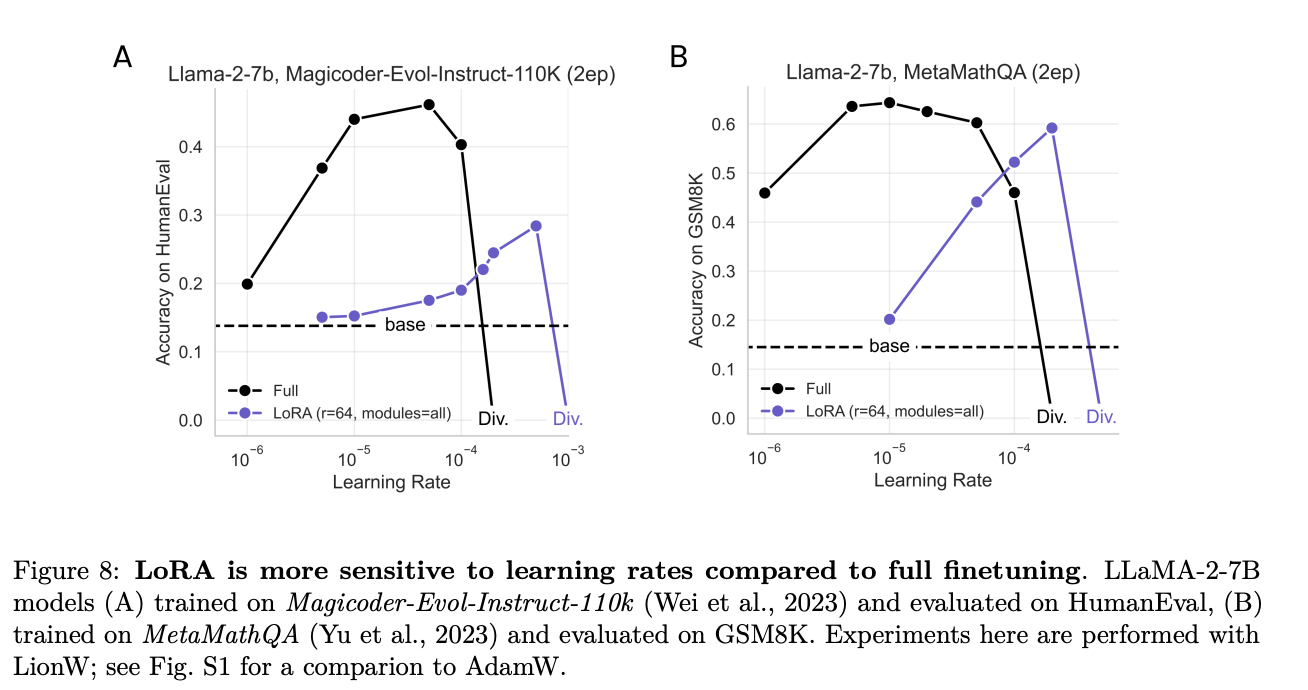
- Training Duration and Data Amount: Extended training periods and larger data volumes tend to benefit full fine-tuning more significantly than LoRA.
Conclusion
While LoRA presents a more memory-efficient method for fine-tuning LLMs, its efficacy varies significantly across different domains and tasks. It serves as a robust tool for maintaining general model performance and diversity but may require careful tuning and realistic expectations regarding its capabilities versus full fine-tuning.
This paper contributes crucial data to the ongoing debate on the most effective ways to fine-tune LLMs, guiding future research and practical applications in AI and machine learning.
Reference
LoRA Learns Less and Forgets Less: https://arxiv.org/abs/2405.09673